
如果你只关注本文末尾代码级别的解决方案,或许没有太多惊喜。然而如果你能完整的阅读下来,相信关于性能问题的解决思路以及指标的取舍还是能带来一些参考价值
背景
相信绝大部分公司的中台系统中都存在仪表盘页面,以 Ant Design Pro 展示的分析页面为例,通常仪表盘页面的形式如下:仪表盘由不同的图表卡片组成,并且允许作者添加、删除卡片,编辑卡片和调整卡片的位置大小等等
图表卡片支持多种类型的图表展现,除了传统的折线图与柱状图外,还支持桑吉图、漏斗图甚至表格等等,以满足产品和运营同学以不同的角度洞察指标的变化。但是无论卡片的展现形式有多么的千变万化,背后都需要后端精确的数据的予以支撑。
考虑到卡片是仪表盘的最小单元,彼此之间相互独立,并且可以被动态的添加、预览。所以在页面的设计阶段,我们将仪表盘信息分开存在在两个实体中:「仪表盘」和「卡片」。仪表盘只存储它拥有的卡片的基本信息,如卡片的ID以及位置和尺寸;而卡片的详细信息以及查询工作则交给卡片独立获取。前端与后端同学约定接口时也是以卡片为中心,我们为卡片准备了两类接口, 为了便于描述,将接口简化和语义化:
/meta: 用于请求卡片的元信息,例如指标、维度、图表类型等/query: 根据卡片的元信息查询图表数据,数据返回之后再进行渲染
之所以要将查询接口与元信息接口拆分开,是因为查询体中除了元信息以外还要整合诸如全局日期,筛选条件等额外信息
基于上述的设计,前端的代码实现也非常简单,我们采取了一种「自治」(或者说是「懒惰」)的思想:仪表盘组件只负责将卡片组件实例以指定尺寸摆放在指定的位置,而至于这张卡片的加载、查询、渲染全权由卡片自己负责。基于这个思路,我们甚至不需要复杂的状态管理框架(如 Redux 或者 Mobx),仅仅依靠视图层的 React 就能够实现。卡片组件的实现借助了 react-refetch 类库,它以高阶组件的形式为数据加载提供便利,伪代码如下:
// CardComponent.js:
import {connect} from 'react-refetch'
@connect(() => {
return {
metaInfoFetch {
url: '/meta',
andThen = () => ({
query: '/query'
})
}
}
})
class Card {
render() {
const queryResult = this.props.query.value
return <Chart data={queryResult} />
}
}
// DashboardComponent.js:
class Dashboard {
return (
<div>
{cards.map(({id, position, size}) =>
<Card id={id} position={position} size={size} />
)}
</div>
)
}
connect能保证 metaInfoFetch在组件加载之初就自动执行,并且执行完毕之后继续执行query查询,并且把结果以属性的形式传递进组件中。
但是没想到前端这种「自治」的解决方案却给产品带来了灾难
产品上线之后,我们得到用户反馈说某些仪表盘页面打开总时是会进入了「卡死」状态,即页面无法滚动,无法点击,甚至浏览器也无响应。即使没有「卡死」,一段时间内页面的交互反馈也会出现滞后的情况。在整理出这些有问题的仪表盘之后,我们发现这些仪表盘都具有一些相似的特征:1) 卡片数量多 2) 卡片需要渲染的数据量大
因为允许用户随意的任意的配置卡片,所以某些仪表盘的卡片数量可以达到 20 甚至 30 张以上,而平均每张卡片需要发出两个网络请求,所以在打开仪表盘的瞬间同时有 40 个以上的请求发出,这显然是超出浏览器的处理能力的,同时浏览器也不允许同一个域下有这么的多并行请求,于是大部分的请求处于队列等待中;随着多个卡片查询结果的返回,这些卡片继续进入图表渲染阶段,如果卡片是分钟级别的折线图的话,考虑到按照 n 个维度拆分的情况,图表需要处理 24 × 60 × n 条数据,这对性能是极大的负担。于是你看到在同一时间内,满负荷的请求发出,众多的卡片在渲染,再加上其他需要执行的脚本,CPU 自然就进入了满负荷的状态,因为「单线程」的缘故,浏览器也就无暇响应用户的输入以及渲染页面了
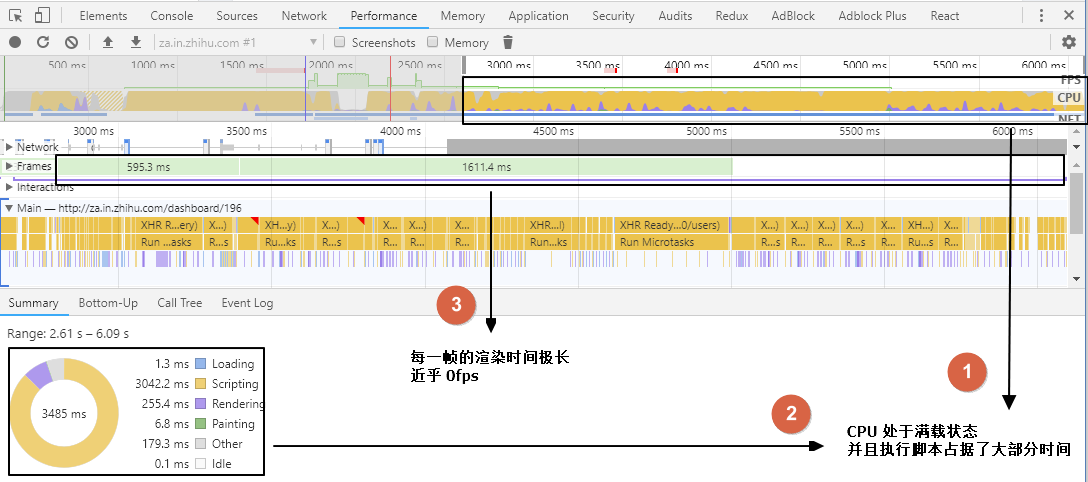
如上图所示,如果我们借助 Chrome 浏览器自带的 Performance 工具观察整个加载的过程,从标注1和标注2可以看出CPU始终处于满载的状态,并且这其中的主要是在执行脚本,并且几乎没有给渲染分配时间,从标注3可以看出,在这段时间内浏览器渲染能力接近 0fps,需要上百秒来渲染一帧
这是事故的现状,接下来就要解决这个问题。
方案
我个人的总结,程序的性能问题好比是人体的疾病,对于治病最有效的两个手段就是经验和工具。经验不仅仅是指你个人曾经遇见过同样的问题,还包括行业内前人的总结归纳。绝大部分问题通过页面的所属功能以及异常行为就能判断出问题可能出在哪里以及应该如何解决,就像医生在秋冬季节看到病人发烧流鼻涕咽喉痛,就能判断出是流感引起以及得出治疗方案了。而对于更复杂的难以通过表象判断的问题,这个时候就需要借助于工具,观察问题发生的时机,(代码)位置,影响面有多广,又或者你只是想通过工具验证你的猜想是否正确而已。
在上一小节的描述的问题中,我无法通过表象判断出问题所在,但是借助工具分析,我们得知是因为高强度的工作造成了 CPU 的满载。这个时候经验就能够派上用场了。
在面对 long task (执行时间超过 50ms以上)时,屡试不爽的解决方案是分片(chunk),也就是把长时间连续执行的任务拆分成短暂的可间隔执行的任务。拆分的好处是能够使得浏览器得以有空隙响应其他的请求,比如用户的输入以及页面的绘制。
我最早接触这个方法是在 Nicholas C. Zakas(「JavaScript高级程序设计」原版作者) 十年前发表的一篇博客中,在处理一个占用时间过长的循环时,他编写了一个很简易的分片函数:
function chunk(array, process, context){
setTimeout(function(){
var item = array.shift();
process.call(context, item);
if (array.length > 0){
setTimeout(arguments.callee, 100);
}
}, 100);
}
虽然现在 callee 已经 deprecated 了,setTimeout也可以使用requestAnimationFrame代替。但是它背后的思考方式并没有发生变化
我们面临的困难并不是一个真实的 long task,而是无数的碎片任务蜂拥而至造成了 long task 的症候群。解决思路依然参考上述办法:要设法给浏览器制造喘息的机会。在这个目标之下,我选择的方案是放弃卡片自治的数据加载和渲染方式,而是采用队列的机制,对需要执行的所有任务做到严格的进出控制。这样能够保证从加载之初就不会给浏览器大压力
即使不是因为性能问题,「自治」仍然不是一个好的设计方案:在开发的后期它的问题已经初现端倪:例如用户需要随时终止所有的卡片的进程、或者按照某些顺序加载,也就是当把它们当作整体时,某些需求很难实现。
这类似于在 React 中是采用 Stateless 还是 Stateful 的方式的抉择。当你在考虑到它们共同属于某个整体时,如父组件和子组件以及子组件之间需要进行相互通信和影响时,应该把大部分组件设计为 Stateless,只有 Top Parent Component 为 Stateful,又或者把状态都集中在 Flux 的 Store 中集中管理。
总的来说, control everything 是一个靠谱的设计准则
产出
性能优化在日常工作中其实处于很尴尬的位置。例如你花费三天为页面或者 App 开发了一个功能,上线之后大家是有目共睹的。然而如果你花费三天时间告诉大家我进行了一次代码优化,大家会对你的产出有所怀疑。所以在优化之前我们最好确定计划提升的指标以便量化产出
然而在这个场景里,我们应该选取哪些指标?我个人习惯将指标划分为「业务指标」和「工程指标」:「业务指标」衡量的是产品的运营状态,例如转化、留存、GMV等等;而「技术指标」面向的是技术人员,例如 QPS、并发数等等。业务指标和工程指标并非是二分法的互斥关系,绝大部分情况下是正相关的,即工程优化的越好,业务指标也会得到提升;但其实也存在相互独立。我常举的例子是,如果 onload 或者 DOMContentLoaded 的时间延长,那么 bounce rate 一定会升高吗?不一定的,只要我能够把 above the fold 内容加载优化的足够快,在 onload 或者 DOMContentLoaded 不变甚至变糟的情况下,bounce rate 其实是会降低的。
在中台的业务场景下,我们并不存在营收或者说是商业化方向的压力,目前看来只有一条,那就是让产品变得可用:即页面能够及时响应用户的输入,及时反馈页面的更新。所以大部分指标都会从工程指标中选取。在前端领域中可以想到,工程指标从「基础」到「复杂」排序分别有:
- onload
- DOMContentLoaded
- SpeedIndex
- First Paint
- First Contentful Paint
- Time to Interactive
但假设我们选取了以上的指标,如何能够准确测量指标?以及测量的结果是否能够正确的反馈工作的成果?这些问题在代码开发完成之后将会得到回答,我们会借助浏览器接口或者工具来复盘这些指标的变化。
实施
回到解决方案中,最后我决定使用一个队列机制严格的控制仪表盘的,其实也是卡片的每一步操作: 1) 请求 meta 信息; 2) 查询报表数据; 3) 渲染卡片
队列机制
首先我们需要一个队列,考虑到请求数据和渲染卡片分别是异步和同步操作,准确来说我们需要一个异步和同步通吃的队列机制。实现的方法有很多种,在这里我借助于 Promise 实现,因为 1) Promise 天生对异步操作有友好支持; 2) Promise 也可以兼容同步操作; 3) Promise 支持顺序执行
我们将这个队列类命名为PromiseDispatcher,并且提供一个feed方法用于塞入需要执行的函数(无需区分异步还是同步),比如:
const promiseDispatcher = new PromiseDispatcher()
promiseDispatcher.feed(
requestMetaJob,
requestDataJob,
renderChart
)
feed 顺序同时也是函数的执行顺序
注意 dispatcher 并不具有保留执行函数返回值的功能,比如
promiseDispatcher.feed(
requestMetaJob,
requestDataJob,
renderChart
).then((requestMetaResult, requestDataResult, renderResult) => {
})
我们不支持以上的使用方法并不是因为实现不了,而是从职责上考虑队列不应该承担这样的工作。队列应该只负责分发并且保证成员执行顺序的正确性。如果你还不明白其中的道理,可以参考 dispatcher 角色在 Flux 架构中的功能
因为篇幅有限,我们这里只列举 PromiseDispatcher 的部分关键代码,整个项目的完整代码会在本文的最后给出。首先是顺序执行机制,这里借用数组的 reduce 方法实现:
return tasks.reduce((prevPromise, currentTask()) => {
return prevPromise.then(chainResults =>
currentTask().then(currentResult =>
[ ...chainResults, currentResult ]
)
);
}, Promise.resolve([]))
然而我们还要兼容同步函数的代码,所以需要对currentTask返回结果是否是Promise类型做判断:
// https://stackoverflow.com/questions/27746304/how-do-i-tell-if-an-object-is-a-promise#answer-27746324
function isPromiseObj(obj) {
return obj && obj.then && _.isFunction(obj.then);
}
return tasks.reduce((prevPromise, currentTask()) => {
return prevPromise.then(chainResults => {
let curPromise = currentTask()
curPromise = !isPromiseObj(curPromise) ? Promise.resolve(curPromise) : curPromise
curPromise.then(currentResult => [ ...chainResults, currentResult ])
});
}, Promise.resolve([]))
然而需要考虑更复杂的情况是,有时候仅仅是单个依次执行任务又过于节约了,所以我们要允许多个任务「并发」执行。于是我们决定给允许给 PromiseDispatcher 配置名为 maxParallelExecuteCount 的参数,用于控制最大可并行的执行个数。针对这个需求,代码上也要做一些修改,使用 Promise.all 来处理多个并发的异步操作情况:
import _ from 'lodash'
const { maxParallelExecuteCount = 1 } = this.config;
const chunkedTasks = _.chunk(this.tasks, maxParallelExecuteCount);
return chunkedTasks.reduce((prevPromise, curChunkedTask) => {
return prevPromise.then(prevResult => {
return Promise.all(
curChunkedTask.map(curTask => {
let curPromise = curTask()
curPromise = !isPromiseObj(curPromise) ? Promise.resolve(curPromise) : curPromise
return curPromise
})
).then(curChunkedResults => [ ...chainResults, curChunkedResults ])
})
}, Promise.resolve([]))
与组件整合
因为项目使用了 Mobx 的关系,这里只展示 Mobx 框架下 Dispatcher 与 Mobx 和 组件配合的代码。相信在其他的框架下也大同小异,关键代码如下:
// Component App.js:
import { observer, inject } from "mobx-react";
@inject('dashboardStore')
@observer
export default class App extends React.Component {
constructor(props) {
super(props);
}
render() {
const { reports } = this.props.dashboardStore;
return (
<div>
{reports.map(({ id, data, loading, rendered }) => {
return (
<ChartCard key={id} data={data} loading={loading} rendered={rendered} />
);
})}
</div>
);
}
}
// DashboardStore.js:
export default class DashboardStore {
@observable reports = [...Array(30).keys()].map((item, index) => {
return {
loading: true,
id: index,
data: [],
rendered: false
};
});
constructor() {
autorun(() => {
this.reports.forEach(report => {
const requestMetaJob = () => {
report.loading = true;
return axios.get("/meta");
};
const requestDataJob = () => {
return axios.get("/api").then(() => {
report.loading = false;
report.data = randomData();
});
};
const initializeRendering = () => {
report.rendered = true;
};
promiseDispatcher.feed([requestMetaJob, requestDataJob, initializeRendering]);
});
});
}
}
注意,因为我们无法手动调用组件的 API 触发组件渲染,所以采用标志位rendered被动的触发卡片的渲染。在组件 <ChartCard /> 中只要做简单的判断即可:
componentDidUpdate(prevProps) {
if (!prevProps.rendered && this.props.rendered) {
this.renderChart(this.props.data);
}
}
验收
为了验证方案,我将本文描述的项目写成了一个 DEMO,源码地址见 hh54188/dashboard-optimize,其中未优化源码文件夹 dashboard-optimize/src/App/, 以及优化之后的源码文件夹 dashboard-optimize/src/OptimizedApp_Basic/。接下来我们使用不同的工具,测量不同方案下的指标变化
未优化的仪表盘 Performance 测量结果:
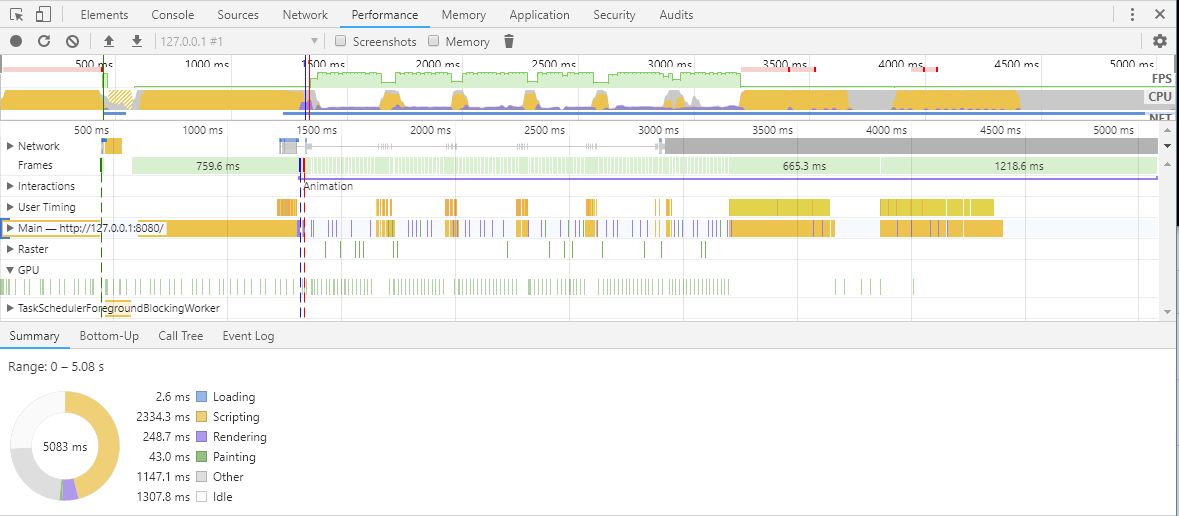
根据图中的红线,蓝线,绿线我们分别能得出一些事件指标的发生时机
- First paint (Green): 443ms
- DOMContentLoaded (Blue): 1.32s
- Load (Red): 1.34s
优化的仪表盘的 Performance 测量的结果
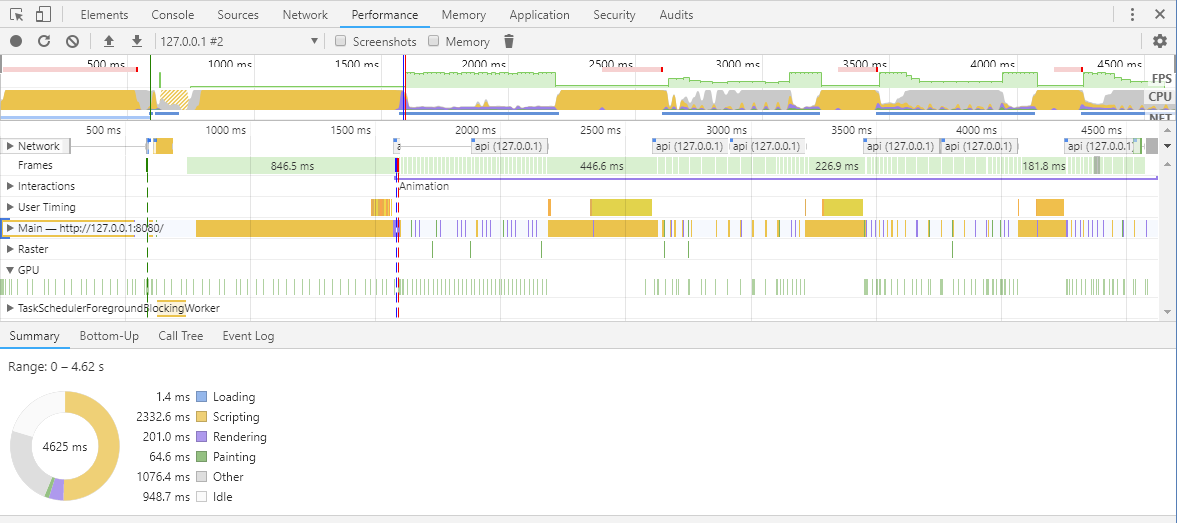
- First paint (Green): 590ms
- DOMContentLoaded (Blue): 1.59s
- Load (Red): 1.59ss
每次的测试数值都可能会有差异,但是总体上看在这个测试工具里,优化过后的仪表盘的三项指标是溃败的。唯一值得庆幸的事情是,优化过后的过仪表盘在初始化之后单帧的渲染效率比未优化的要高,未优化的仪表盘甚至某一帧渲染超过 1 秒
然而如果换一种测量手段呢?比如 API?我们尝试使用 PerformanceObserver,在 html 文件里加入如下代码
const observer = new PerformanceObserver(list => {
for (const entry of list.getEntries()) {
const metricName = entry.name;
const time = Math.round(entry.startTime + entry.duration);
console.log(metricName, time);
}
});
observer.observe({ entryTypes: ["paint"] });
打印的结果如下:
- 未优化
- first-paint 1349
- first-contentful-paint 1349
- 优化后:
- first-paint 1023
- first-contentful-paint 1023
在这个测试手段下我们得到了相反的结果,并且未优化的仪表盘的测试结果非常不稳定,从九百毫秒到两千毫秒都有可能发生。然而如果你此时又通过 tti-polyfill 测试 Time to Interactive 的话,未优化的仪表盘又领先了一大截。
为什么出现这样的情况?因为不同的工具、API 对指标的测量方式不同,以及口径不同
以 TTI 指标为例,很明显优化方案下用户输入一定会比未优化方案更快的得到响应,但是为什么未优化方案的测量结果会更好?因为浏览器对于 TTI 的理解和我们不同:
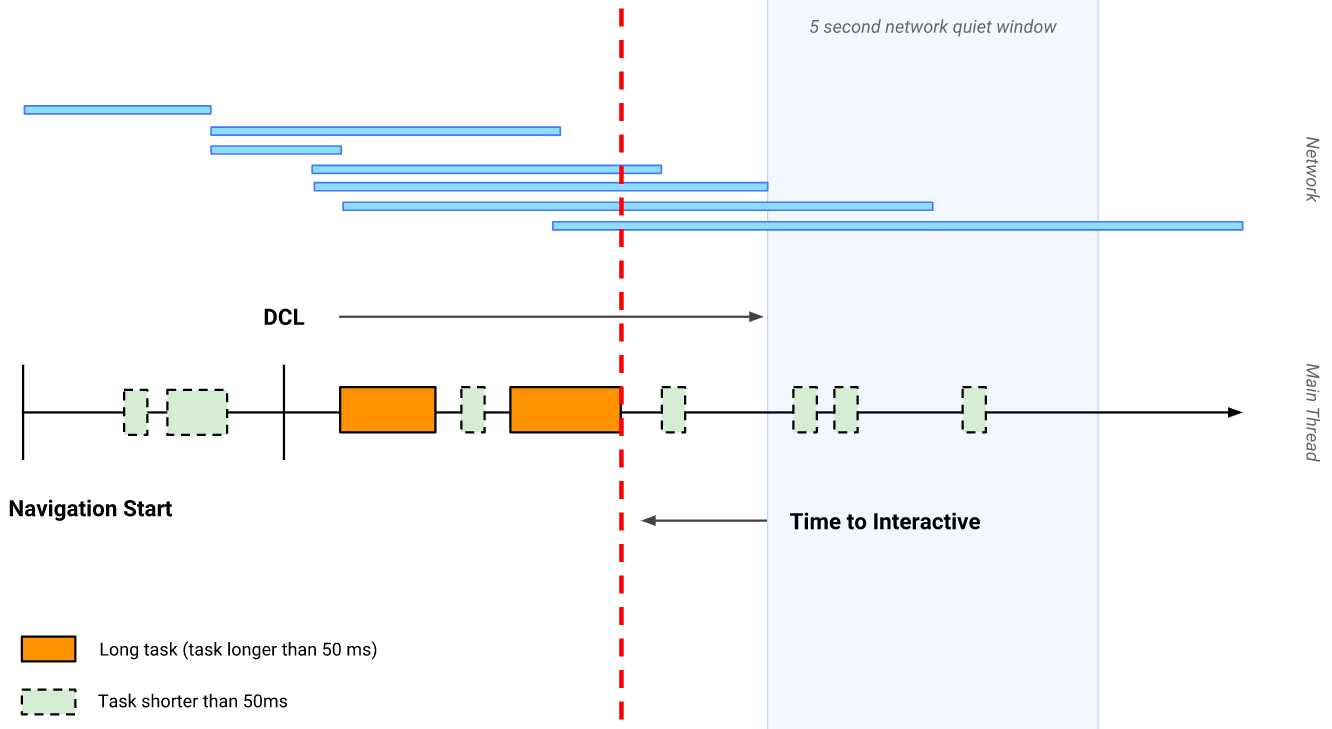
- 首先找到一个接近 TTI 的零界点,比如 FirstContentfulPaint 或者 DomContentLoadedEnd 时机
- 从临界点向后查找不包含长任务 (long task) 的并且网络请求相对平静的 5 秒钟窗口期
- 找到之后,再向前追溯到最后一个长任务的执行结束点,那就是我们的要找的 TTI
所以在优化方案中,因为网络请求始终在发生,所以 TTI 测量结果异常糟糕
在实施到真实产品中之后它的确是有效的。但是在文章的最后,我无法用一个恰当的工具测量出的恰当的指标以宣告它,或许这个时候我们可以考虑使用更具针对性的业务指标来验证优化的结果,例如用户的页面的停留时间,浏览器标签的切换次数以及操作频率等等,但这些埋点和指标设计都超出本文范围之外了。
你可能会喜欢