
在阅读本文之前你首先要对前端的Flux架构和Redux架构有所了解(或者可以通过这篇文章对Flux进行扫盲),因为本文就是介绍Flux架构和Redux架构背后的设计思想。
Flux和CQRS很像,Redux与CQRS很像,Flux也与Redux很像。我不确定Flux是否受到了CRQS的启发,但Redux作者在Redux.js官方文档的Motivation一章里,在最后一段很明确的提到:
Following in the steps of Flux, CQRS, and Event Sourcing, Redux attempts to make state mutations predictable by imposing certain restrictions on how and when updates can happen.
我们已经知道了什么是Flux,但关于CQRS和Event Sourcing大部分人并不了解。其实DDD/CQRS/ES是形影不离的三个概念,通常在谈论其一时也会覆盖其二。在这篇文章里都会统一做一次扫盲,并看看Redux或者Flux是如何借鉴它们的。
Model & ORM(Object-Relational Mapping)
虽然Model和ORM不是这篇的主角,但它们是会涉及到的两个概念,所以提前进行介绍。
Model,译为模型,是对业务逻辑中涉及到的概念的抽象。比如我们需要开发一个“客户管理系统”,那么“客户”概念就可以抽象为一个模型,有关客户的种种行为,例如创建客户,注销客户,查看客户等操作都可以在模型中得以体现,也就是业务逻辑封装在模型中。MVC中的Model即是如此,例如在系统界面上查看客户信息,就需要调用客户模型的获取客户信息的方法,用户信息视图的Controller会这么写:
var CustomInfoController = function (req, res) {
var customInfo = CustomModel.showInfoById(req.body.id);
}模型和它对应的数据之间的关系却没有那么直观,我们有“客户”这个模型或者说是概念,但真正关于客户的数据或许存放在多个数据库表中,甚至很跨多个物理服务器,或者showInfoById这个方法使用了事务,使用了存储过程。也就是说,通常我们在使用“模型”这个字眼时,我们不考虑它的底层是如何存储,表如何设计,接口是如何实现的。模型是一个工具,它告诉我们系统由什么组成,是如何工作的,还有不同部分之间如何通信,依赖,协作等信息。这一类Model可以称之为Business Model或者Domain Model,但不一定是Object Model。Object Model意味着每一个模型都可以以面向对象编程中类的形式体现出来,但在DDD(Domain-driven design,另一个与CQRS相关的概念,放在最后介绍)的概念中,不是每一个模型都适合用类去表达(虽然代码实现中我们或许别无选择)。
另一种Model我们可以称之为Data Model,如果说Domain Model是对现实概念的映射,那么Data Model则是对数据库的映射。这种映射可以用一个更专业的词汇体现出来,就是ORM(Object-Relational Mapping),即把数据库的表结构(Schema)映射为面向对象中的类。
当我们想通过数据库查询用户信息时,代码通常是这么写的:
// 创建数据库连接
var connection = mysqljs.createConnection(mysqlStr);
// 执行查询语句
connection.query('SELECT * FROM custom JOIN (address, avatar) ON (cutsom.id = address.id AND address.id = avatar.id) WHERE custom.id=' + userId, function (err, results) {
})我们必须要自己书写数据库查询语句,直接与数据库打交道。
而如果通过ORM将数据库映射为对象之后,我们操作的就是对象,而不再直接和数据库打交道了,上面的语句就可以改为:
Custom.get({
id: userId
});CQRS
CQRS全称为Command Query Responsibility Segregation,顾名思义“命令与查询职责分离”。“职责分离”我们理解,但怎么区分“命令”与“查询”,他们的职责又分别是什么?
命令与查询的根本区别在于,是否改变数据的状态。例如增、删、改操作即归属于“命令”,因为这些操作会导致数据被修改;而查询操作只求返回结果,并不修改数据,所以归属于“查询”(查询归属于“查询”,好吧,听上去像废话)。另一个区别在于,“命令”操作不需要返回值(当然我们在编码时需要有返回来告诉我们修改是否成功),而“查询”需要。
简单来说,CQRS作用在于把数据的读和写分离。读写操当然是隔离的,这里的分离相对的是传统编程中一视同仁的编写CRUD(Create, Read, Update, Delete,增删改查)接口代码。CQRS主张对“读”和“写”的接口做不同的设计,编码和优化。而之所以要做这样的分离,原因有以下两点:
-
在许多业务场景中,数据的读和写的次数是不平衡,可能上千次的读操作才对应一次写操作,比如机票余票信息的查询和更新。所以把读和写操作分开能够有针对性的分别优化它们。例如提高程序的scalability,scalability意味着我们能够在部署程序时,给读操作和写操作部署不同数量的线上实例来满足实际的需求。
-
通常来说,“写”操作比“读”操作更加复杂,无论是业务逻辑方面还是技术方面。例如写操作首先要验证数据的合法性和完整性,存储中会涉及事务,存储过程,同时还要考虑数据冗余,数据同步;而读操作则完全没有类似的要求。把读和写分离相当于隔离了复杂操作,分离便于我们更好的独立维护它们,
至于CQRS的实现,则参考下图:
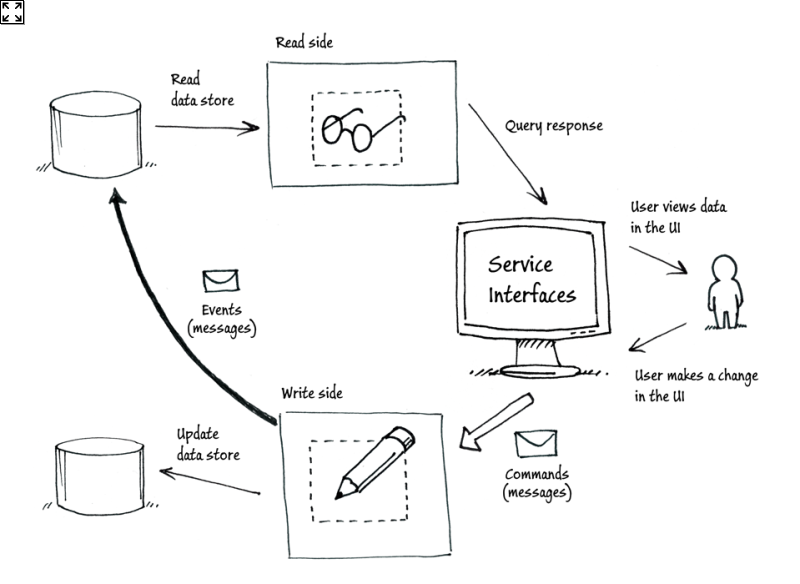
图正如上文描述所说,所有的写操作请求都转发给write side, 而视图则从read side查询数据。从这里你可以看到Flux架构的影子:当数据在write side发生更改时,一个更新事件会被推送到read side,通过绑定事件的回调,read side得知数据已更新,可以选择是否重新读取数据。下面这张Flux流程图或许能够帮你回忆起Flux:
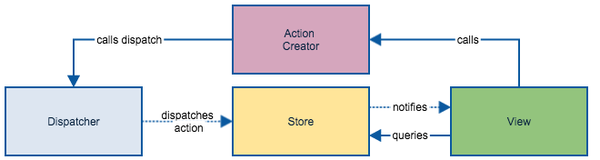
这里我们要辨别一点Flux与CQRS流程图中的不同点。在CQRS中,write side和read side分属于两个不同的domain model,各自的逻辑封装和隔离在各自的Model中。而在Flux里,业务逻辑都统一封装在Store中。
另有一点关于CQRS流程图中非常重要的是,请求到了Model里终究还是要转化为对数据的操作,既然读和写的业务逻辑都独立开了,那么被读和被写的数据也需要隔离开吗?独立的数据库当然会有更好的性能,但随之而来的是数据延迟和数据同步的问题。所以在CQRS实践的过程中还是需要有很多要考虑的问题。
Event Sourcing
在介绍Event Sourcing之前,我们先好好了解一下什么是Event。在上一篇关于Event Bus的文章中,我们把Event与Command做了比较,总结出了事件(Event)的几个特征。现在请让我们继续补充完整这些特征:
- 事件发生在过去。比如“用户把商品添加进购物车”,就是一件已经发生的事情
- 事件是不可以更改的。因为它已经发生了,你没法更改或者撤销(除非你是奇异博士,能够操控时间)
- 事件是单向的消息。事件的发布源只有可能是一个,而事件的订阅者则可以有很多
- 事件发布时会附上与事件有关的信息。例如“ID为123用户的把ID为456的商品添加进了购物车”
- 最后,事件在Event Sourcing的场景中,一定是用于表达业务目的。例如上面的“ID为123用户的把ID为456的商品添加进了购物车”,意味着我们要检查库存,更新用户订单数据。在这个场景中事件不是用来表达一般的技术事件,比如点击动作,组件通信等。
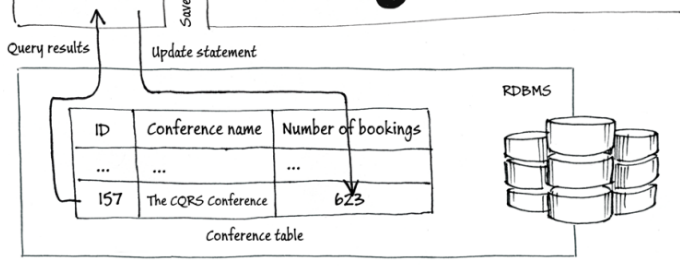
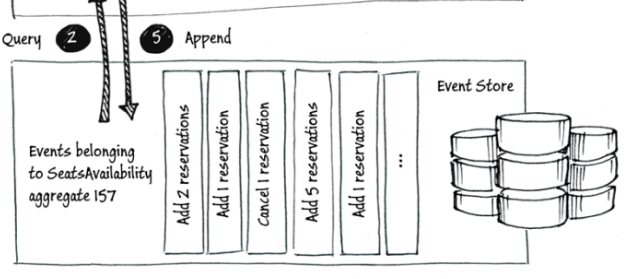
数据存储大致可以划分为两种方式,一种是直接存储数据结果,例如商品的库存,我们只关心还剩下多少件,所以存储结果是一个数值;另一种是存储每一次的更改,好比记账,我们要存储每次支出多少,每次收入多少,所以记录的是一连串数值。这种情况下我们不太在意最终结果,但是当需要最终结果时,只要把每次的差异累加即可。Event Sourcing就是指后面这种存储方式。用专业术语描述就是:Event Sourcing是一种通过记录“数据发生改变的历史事件”,来持久化当前状态的方式。
常规存储:
Event Sourcing 存储:
为什么我们要使用Event Sourcing?我们可以找到以下优点:
- 高性能:事件是不可更改的,存储的时候并且只做插入操作,也可以设计成独立,简单的对象。所以存储事件的成本较低且效率较高,扩展起来也非常方便。
- 简化存储:事件用于描述系统内发生的事情。我们可以考虑用事件存储代替复杂的关系存储。
- 溯源: 正因为事件是不可更改的,并且记录了所有系统内发生的事情,我们能用它来跟踪问题,重现错误,甚至做备份和还原
- 被其他系统使用:上一篇文章说到事件可以作为不同服务间的通信方式,所以事件也可以被推送到自他的系统中被二次利用
- 附加价值:我们能把事件历史作为大数据的数据源,从中统计出有价值的信息
但最终还是要回归理性,毕竟以结果为导向的数据存储和以过程为导向的数据存储适用的业务场景是不同的。Event Sourcing只是为我们将来设计系统时多提供了一种可能性,最终还是需要具体问题具体分析。
说到这里,你一定会觉得在Redux中似曾相识。Redux强调的是应用的“状态”,状态之间是独立的、连续的但无关联的,这与Event Sourcing中的事件的独立和序列化不谋而合;另一个不同之处在于,Redux中的每一次产生的状态都是完整的,而Event Soucing中事件记录的是状态之间的差值。对了,Redux中的状态是有限个能够枚举出的。
DDD( Domain-Driven Design)
就像文章开头说的,DDD 和Flux与Redux并没有直接的联系,但是当你谈到CQRS时,你不得不提DDD(虽然我也不知道为什么,文章总是拿他们放在一起比较)。
这一小节当然没法完全展现DDD的全貌。而如果你又没有兴趣读完560页的完整版的Domain-Driven Design: Tackling Complexity in the Heart of Software的话,可以尝试快速版的domain driven design quickly。建议阅读英文原版,中文版的体验比较糟糕。以下的部分内容也都摘自这个快速版本。
个人的理解,DDD是一套关于软件设计的方法论,简单来说就是它教你怎么设计软件:例如告诉你可以把软件划分为哪些部分,为什么这样划分,以及不同的部分应该如果秉承什么样的理念进行开发,同时还要顾虑到哪些禁忌等等。这些都是概念理论上的,与具体的开发语言无关。
我不是传统软件行业出身,虽然在大学时候编写过ASP.NET和WinForm代码,但也没有太多深刻的体会,相信大部分人也是如此。但只要你编写过稍复杂的程序,后端服务也好,前端MVC也好,相信在你阅读DDD的时候还是会深有感触,会认可书中提出的观念和解决方案。
Domain-Driven Design,这个名字已经告诉你它的重点,即Domain Driven——业务驱动。在书的开头,他首先强调的就是业务的重要性:
You cannot create a banking software system unless you have a good understanding of what banking is all about, one must understand the domain of banking
Is it possible to create complex banking software without good domain knowledge? No way. Never.
如果你想开发银行的业务系统,你首先要了解银行的所有业务是如何运作的,你甚至要比银行的柜台人员还要熟悉他们的业务,因为他们可能在表达需求时会有遗漏,会表达有误。
接下来需要对业务进行抽象,抽象为业务模型,也就是本文开头说的(Domain) Model。Model非常重要,它是软件工程师和提出需求业务人员交流的基础。软件设计师,程序员和业务人员需要一门通用语言(Ubiquitous Language)来进行业务上的交流,虽然对于程序员来说我们有面向对象,有UML语言,有各种图例辅助我们表达和理解需求,但业务人员对这些一无所知。而无论这门通用语言具体形式如何,它都必定是基于Model的。
当我们借助于Model把需求确定下来之后,接下来的任务就是考虑如何把Model翻译为代码。原则上我们应该使得软件的架构设计和Model保持一致,那么当业务发生修改时,改动就能直观的反馈到代码中。而在把Model翻译为代码的过程中,存在一些常见的模式,例如书中总结了软件中常见的一些组件或者概念:
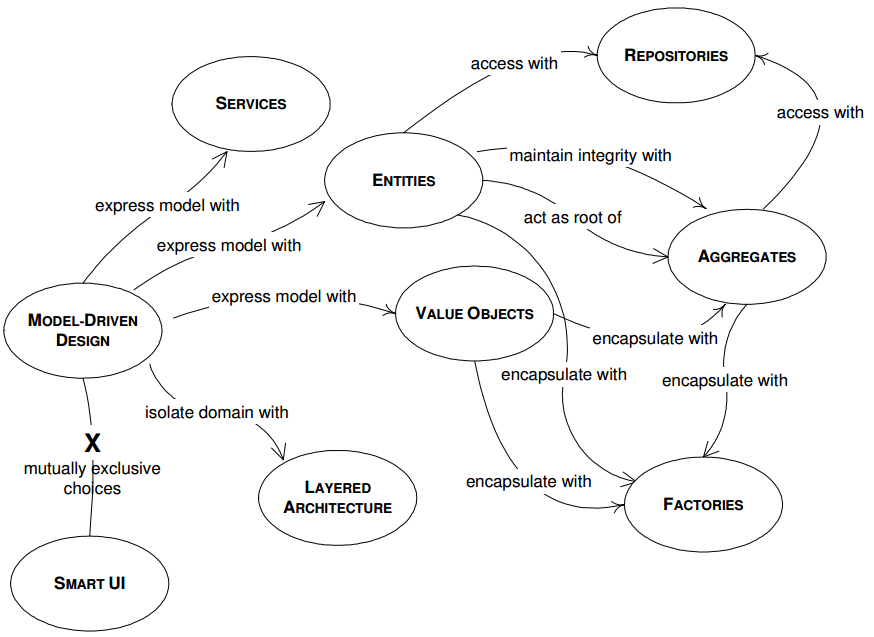
- 实体(Entities):具有身份标识的对象。比如银行的个人账户信息,如果我们把账户信息抽象为一个对象的话,那么这些对象都有唯一的id用于辨别它们。实体的特点就是具有身份标识(identity)。
- 值对象(Value Object):虽然对象可以是实体,但不是每一个对象都必须是实体。有时候我们不关心它具体是谁,我们关心的是它附带的属性值,比如消息。值对象通常可以被共享,销毁,复制。
- 服务(Services):业务模型中总存在一些行为或者操作不属于任何对象或者类。例如当我们把钱从一个账户转到另一个账户,转账这个行为究竟是属于发出方还是接收方?一旦发现这样的行为,最好把它定义为“服务”。服务有以下特征:
- 服务提供的操作是一个业务概念,不属于任何实体或者值对象
- 执行操作会影响到业务模型中的其他对象
- 服务操作是没有状态的
- 工厂(Factories):假设对象A想创建对象B,常规情况下只要调用B的构造函数并且传入参数就可以了。但是当创建对象B的流程变得复杂之后,例如创建时可能需要传入其他的对象,其它的对象之间又互有依赖。那么这实际上我们把B的细节暴露给了A,这是一个坏的设计。所以我们应该把创建复杂对象的职责转移到一个独立的对象中,这就是“工厂”。虽然工厂通常在业务模型中没有明确的职责,但仍然属于软件设计的一部分。
以上只是常见模式的一部分。模式的好处在于,当你想把业务模型翻译为代码时,你可以把业务模型中的概念,根据它们的特征、职责套入这些模式中。这会为你节省下不少的时间。这不仅仅是“模式”的优势,还是整个DDD的优势。DDD像是一个架构模板,告诉你不同的业务在代码层面应该如何组织,如何通信,如何划分层级。以及在完成之后,如何持续的改进。
结束语
关于设计思想这一专题,这里就告于段落。这两篇只是对很多概念做了简短和入门的介绍。这一专题的目的不在于教大家如何掌握和运用这些技术,而是做一次科普,或者说是分享。相信对大家理解Flux和Redux有不少的帮助。同时也为大家今后解决技术上的问题增添一些思路。
参考文章合集
https://www.site2share.com/folder/20020515
你可能会喜欢
- CSS 里的整洁架构
- 前端架构 101(一):在谈论它们之前我们需要达成的共识
- 前端架构 101(二): MVC 初探
- 前端架构 101(三):MVC 启示录:模块的职责,作用域和通信
- 前端架构 101(四):MVC的不足与Flux的崛起
- 前端架构 101(五):从 Flux 进化到 Model-View-Presenter
- 前端架构 101(六):整洁(Clean Architecture)架构是归宿
- 【译文】【前端架构鉴赏 01】:Angular 架构模式与最佳实践
- 【译文】【前端架构鉴赏 02】:可拓展 Angular 2 架构
- 【译文】【前端架构鉴赏 03】:Angular 与 MVP 模式
- 微前端说明书
- 从美团这篇文章聊聊微前端的聚合问题
- 写给前端看的架构文章(1):MVC VS Flux
- 从MVC模式在前端开发中的局限性谈起
- Flux与Redux背后的设计思想(二):CQRS, Event Sourcing, DDD
- Flux与Redux背后的设计思想(一):Command Bus, Event Bus, Service Bus