
最近给我的播客网站新增了搜索功能。与实现常规搜索功能不同的是,它依赖的不是 MySQL 或者 ElasticSearch,而是 Vector DB。准确来说是将数据持久化在本地的 ChromaDB。这不是一篇介绍如何实现它的教程,而是借此契机聊聊传统编程经验在 AI 开发中是否依然受用。本文无关代码,也无关你是否体验过 AI 编程,可放心阅读
岔路依然存在
对于外行来说,从所有关于 AI 的“时髦”词汇中选择一个方向开始是颇为困难的一件事:neural network,、machine learning、deep learning,、tensorflow、pytorch、LLM ……因为你不确定你想实现的功能仰仗的是哪一项关键技能。这样的顾虑是对的,如果你的目标是制作一款面向 2C 受众的 AI 工具,那么理论知识不必摆放在最高优先级,因为它成为不了你的单点依赖。
这并非是臆想而是感受,不妨去 medium 上搜索主流 AI 框架(LangChain、llamaindex)的热门文章 ,我无法一言以蔽之它们有关什么,但我可以肯定它们无关什么——深度。medium 文章善于服务于读者而不是还原技术本身。与此同时 AI 框架官方也热衷于提供量大管饱的 cookbook(或者说是 how to)。cookbook 意为“菜谱”,顾名思义它等同于即抄即用的可工作代码。于是有意思的事情出现了,如果你的应用同时涉及 LangChain + OpenAI + Pinecone,你会发现可以:1)在 LangChain 文档中找到如何将 LangChain 分别与 OpenAI 和 Pinecone 集成;2)在 OpenAI 的 cookbook 中找到如何将 OpenAI 分别与 Pinecone 和 LangChain 集成;3)在 Pinecone 的文档中找到如何将 Pinecone 分别与 OpenAI 和 LangChain 集成。喔,三倍胜算。似乎设法交付代码而非理解技术成为了 AI 开发者之间达成的共识。
我们甚至可以继续在硬件上懒惰下去:想运行 Llama?不必实装 4090;想部署 AI 应用?不必从 0 开始配置环境——如今白菜价的 AI Inference (例如 together.ai, groq)满大街都是。没办法,全世界都想让程序员专心写好业务代码。有时候我实在想不清这究竟是我们迫使技术进步,还是技术迫使我们躺平
换一个角度看同样成立:我读过最好的有关 AI 编程图书是《Python神经网络编程》,它让我惊讶的意识原来我也可以构建自己的神经网络,高中代数知识就足够了。本书的英文原版《Make Your Own Neural Network》在亚马逊上收获了收获了数以千计的好评。但令人感到吊诡,同样也令人感到遗憾的是,这样一块都对我来妳足珍贵的知识片段,它的缺失与否,不会对我接下来编写的代码产生任何影响。

虽然广义上的 AI 已经不再是只有少数人可以掌握的科学,而是多数人都可以涉猎的学科,但它专业的影子依然存在,例如 tensorflow 文档内的参数说明中随处可见对论文的引用,高情商的说这给了这门技术极大的探索空间,但事实是,对于想了解技术全貌的非该专业的开发者而言,这成了一道不低的门槛。各类延展的阅读材料就像是交付途中的岔路,极具诱惑的同时也伴随风险。正如上文我们观察到,如果你最得心应手的开发工具是开箱即用的 AI 框架,那么我的建议是暂且跳过这大大小小的兔子洞,将探索技术全貌的好奇心搁置一旁。
我想起了一个笑话:千万不要向专家咨询你的疑问,否则你的一个疑问会变成三个疑问,因为他会用另外两个你同样不理解的概念去解释它——这也是为什么 AI 开发里延伸阅读晦涩难懂的原因。公允的说“岔路”其实是程序员的营养来源:A 将我带向 B,B 既是我的新收获,也丰富了 A 的轮廓;但在 AI 这里,光是 A 就会将你带向 B、C、D、E
“在任何一项足够先进的技术和魔法之间,我们无法作出区分(Any sufficiently advanced technology is indistinguishable from magic)”——这是克拉克基本定律(Clarke’s three laws)最广为人知的一则。这正是当下的现状:层出不穷的 GPT 恰恰是童话里魔镜的现代都市版。我深愔我擅长运用魔法,而非创造魔法。
框架依然有效
LangChain 是时下最夯的 AI 框架,以某个与 OpenAI 进行对话的场景为例,使用 OpenAI 原生 SDK 的代码如下:
from openai import OpenAI
client = OpenAI()
response = client.chat.completions.create(
model="gpt-4o-mini",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Who won the world series in 2020?"},
]
)
使用 LangChain 的版本如下
from langchain.prompts import SystemMessagePromptTemplate, HumanMessagePromptTemplate, ChatPromptTemplate
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(model_name="gpt-3.5-turbo", temperature=0.5)
prompt = ChatPromptTemplate.from_messages([
SystemMessagePromptTemplate.from_template("You are an expert data scientist"),
HumanMessagePromptTemplate.from_template("What's your name?")
])
chain = prompt | llm
res = chain.invoke({})
在上面的例子中,LangChain 将特定角色的 prompt 封装为特定类型的模板组件。
框架的其中一项优势是你无需再关心底层具体调用的模型,这也是 LangChain 的设计哲学之一: integration-agnostic。如果你想把 OpenAI 替换为 Gemini,那么只需将代码中有关具体模型的部分更新即可,:
from langchain_google_genai import ChatGoogleGenerativeAI
llm = ChatGoogleGenerativeAI(model="gemini-1.5-pro")
但并非所有人对 LangChain 都持有肯定的态度。以 HackerNews 上的该篇讨论为例,对于 LangChain 的批评都汇聚成同一个声音:不恰当的抽象。由此带来的副作用包括但不限于难以进行定制化开发,大量额外的学习成本、并不诱人的投入产出比等等。
首先我不认为应该放大 Hacker News 的声音,那份弥漫在程序员群体中傲娇文化在仍旧弥漫在此:我比你聪明,所以我来告诉你为什么你是错的。
其次上面所提到的框架问题,并不是只属于 LangChain 的特例而是开发中的常态,我记得我第一次面对框架无法支撑需求的情况时,得到的指令是去修改 jQuery 源码。无论是在项目启动阶段还是业务拓展后期,类似的问题一定会遇到。为了适配框架去修改设计,亦或是当框架不再满足需求时开始物色新的技术选型,都是情理之中的事情。
想要理解 LangChain 的争议,最好的类比是 ORM:为什么明明用 SQL 就可以解决的问题, 我需要在此之上覆盖另一层抽象,把它翻译成另一套编程“语言”?就我个人的开发体验而言,我同时感受过来自 ORM 正面和负面的反馈:1)在小型项目上使用 ORM 的确毫无性价比可言:在编写 ORM 语句的成本与编写 SQL 相比不相上下的同时,维护成本却无形中被加倍,因为还需要额外大量的集成工作有待完成,集成 ORM 的人很痛苦,使用 ORM 编写业务代码的人很舒服 ;2)但在大型项目上当有待裸写的 SQL 代码增长到几十上百行时,ORM 代码会具有更好的可读性和更低的维护成本。
我想表达的是在 LangChain 的选型上,应该尊循的是我的体感而非他人的看法。也许 LangChain 的抽象并非是最完备的那个,但它一定是最不差的那个,给予我们这些新入场的玩家了解全貌的机会
工程问题依然成立
想要实现 Vector DB 搜索(其实我一开始是奔着 RAG 去的),将结构化数据 embedding 为 vector 是必不可少的一个环节:

用一段 notebook 代码实现上述流程的单次运行非常简单。但实际上令我头疼的问题恰恰不是最核心的业务代码,而是如何让整个程序持续运行。这意味着有更多的问题需要处理:
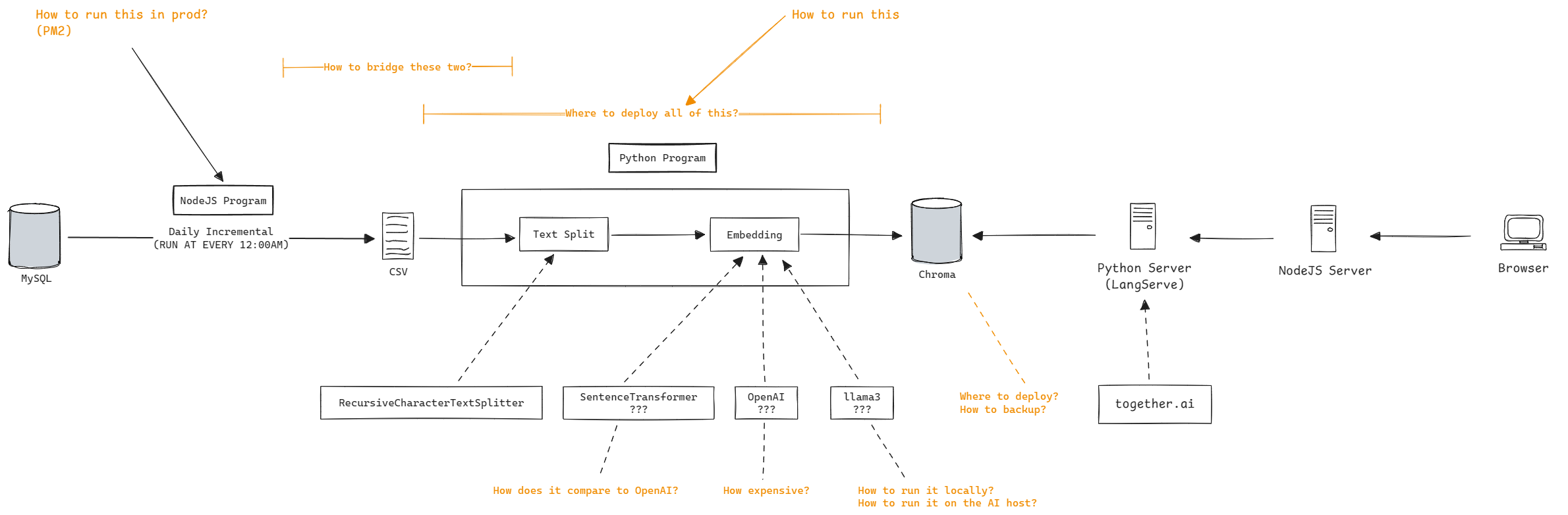
以上截图并非是为这篇文章重新绘制,而是在写这个程序时的真实设计。如果你有仔细观察上图中高亮部分,就会发现它们并不新鲜,无非是有关成本、服务间通信、CI/CD。
事实上最终的版本和上图的设计有不少差异,例如
- 没有使用到 OpenAI 或者 Llama 来进行 embedding,而是使用 shibing624/text2vec-base-chinese 模型
- 选择使用 FastAPI 而不是 LangServe 来对外提供 web 服务
- 整个 LangChain 与 Chroma 服务单纯用最原始的方式部署在 VPS 上,no docker,no AI inference
所有这些选择只基于两点约束:
- 我是 one man team,我希望把所有的维护成本和金钱成本降至最低,额外的组件和抽象并不会带来更多的收益
- 我的 MySQL 服务目前正在承受巨大的压力,搜索只会让它恶化。为了隔离风险我选择将搜索服务独立,从技术栈到数据的独立
所以正如你所见,我们设计、考量在新的上下文中并非发生了任何的质变。
你可以说写代码是一碗青春饭,但并不意味着经验在这里无效。如果你现在去搜索 Vector DB,得到的结果会让你眼花缭乱:ChromaDB、Pinecone、SingleStore,甚至连 Supabase、Firebase 此类的 BaaS 都提供 Vector 数据的存储服务。如何去进行技术选型,如何适配当下的服务,如何快速深入一个领域然后成长起来,这类能力不是从地里长出来的。我妈至少有一件事说对了, 小学的确是给初中打基础的时候,指望着小学垫底然后初中一鸣惊人是不现实的。